企业里的规章制度、管理办法、会议细则、制度汇编,往往都躺在一个又一个 Word 文件里。
文件越积越多之后,真正让人头疼的并不是“有没有文件”,而是:
- 找不到需要的那一版
- 找到了文件,却翻不到对应条款
- Word 里的自动编号结构没有被很好利用
- 想看“第一章、第一条、(一)”这样的层级关系时,只能靠手动滚动
- 想把重点内容摘出来做复盘或汇编,也很麻烦
最近我把自己做的一个桌面软件整理开源了,它叫 RuleScope。
这是一个专门面向 规章制度类文档 的浏览、检索与大纲识别工具,重点解决“Word 文档结构化阅读”这件事。
为什么会做这个工具
传统文件管理方案大多更关注“存储”和“上传”,但对于规章制度类文档来说,真正重要的是 结构。
这类文件通常有非常明确的层级,比如:
- 第一章
- 第一条
- (一)
- (二)
这些编号在 Word 里很多时候不是普通文本,而是 Word 自动编号。
这意味着,很多通用解析方案虽然能把正文读出来,却未必能正确识别出文档大纲层级。
也正因为这个问题,用户在阅读制度文档时经常会遇到两种体验不佳的情况:
- 文档能打开,但没有大纲
- 大纲有了,但“第一条后面的正文”也被错误塞进标题里
RuleScope 的核心目标,就是让这类文档在桌面端拥有更接近“规范阅读器”的体验。
它能做什么
目前 RuleScope 主要包含以下几个能力:
- 上传 Word、TXT、PDF 文件
- 自动提取并展示文档内容
- 识别 Word 自动编号结构
- 生成可导航的大纲
- 在文档内部快速搜索
- 收藏高亮片段并添加笔记
- 支持中英文界面切换
- 提供便携版桌面运行方式
对于规章制度、管理制度、董事会细则、内控制度等文件来说,这些能力组合起来,已经能覆盖日常的大部分阅读和归档场景。
自动识别 Word 大纲,是这个工具最重要的部分
RuleScope 里最关键的一项能力,就是对 Word 自动编号的识别。
它不是简单地把 .docx 转成纯文本,而是额外去读取 Word 文档里的编号定义信息,再结合正文结构做解析。
这样一来,就能把常见的制度文档层级正确映射出来:
第X章识别为H1第N条识别为H2(X)识别为H3- 其他内容保持为正文
并且,这里还专门处理了一个很常见的问题:
“第一条后面的正文,不应该一起进入大纲。”
也就是说,正确的结构应该是:
# 第一章 总则 ## 第一条 正文内容…… ### (一) 正文内容……
而不是把整段正文都塞进标题里。
这个细节对阅读体验影响非常大,因为一旦标题和正文混在一起,大纲就会变得又长又乱,失去导航价值。
上传页:尽量简单,尽量清楚
我希望这个软件在使用上尽量没有门槛,所以上传页做得比较直接:
- 支持点击和拖拽上传
- 支持批量选择文件
- 明确显示支持格式和大小限制
- 上传前保留文件确认区
对于很多内部工具来说,上传页往往是最容易“功能堆砌”的地方,但对用户来说,最重要的是:一眼就知道能不能传、怎么传、传完会怎样
文件管理页:从“文件列表”变成“结构化阅读器”
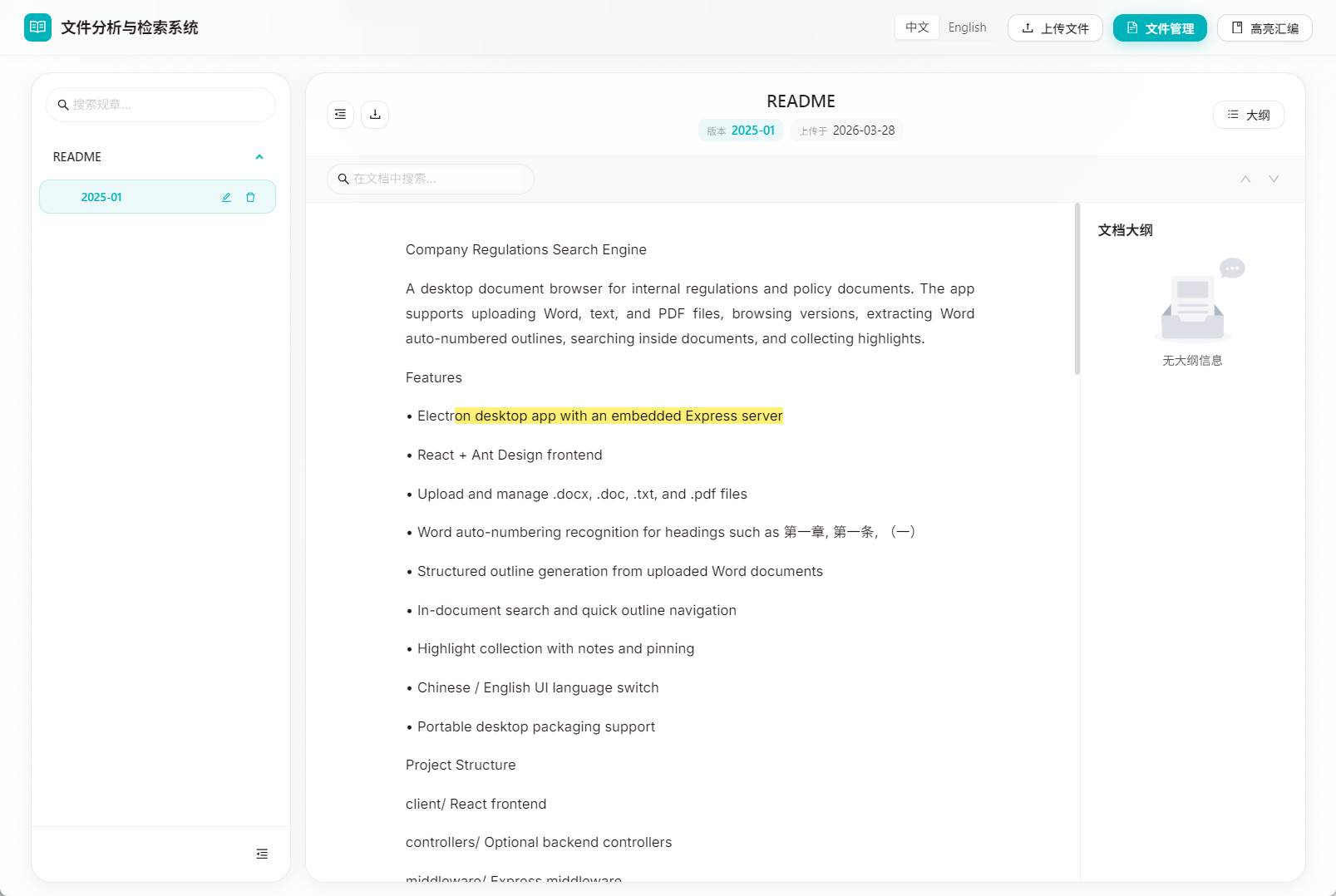
相比传统文件列表,RuleScope 更像一个“制度文档阅读器”。
它把阅读页面分成了几个重点区域:
- 左侧:文档列表与版本入口
- 中间:正文阅读区
- 右侧:自动提取的大纲
- 顶部:版本信息、上传日期、全文搜索、下载等操作
这样做的好处是,用户不需要反复打开 Word,再滚动到某个章节,而是可以直接:
- 通过大纲跳到目标位置
- 在正文中搜索关键词
- 对重点内容做高亮摘录
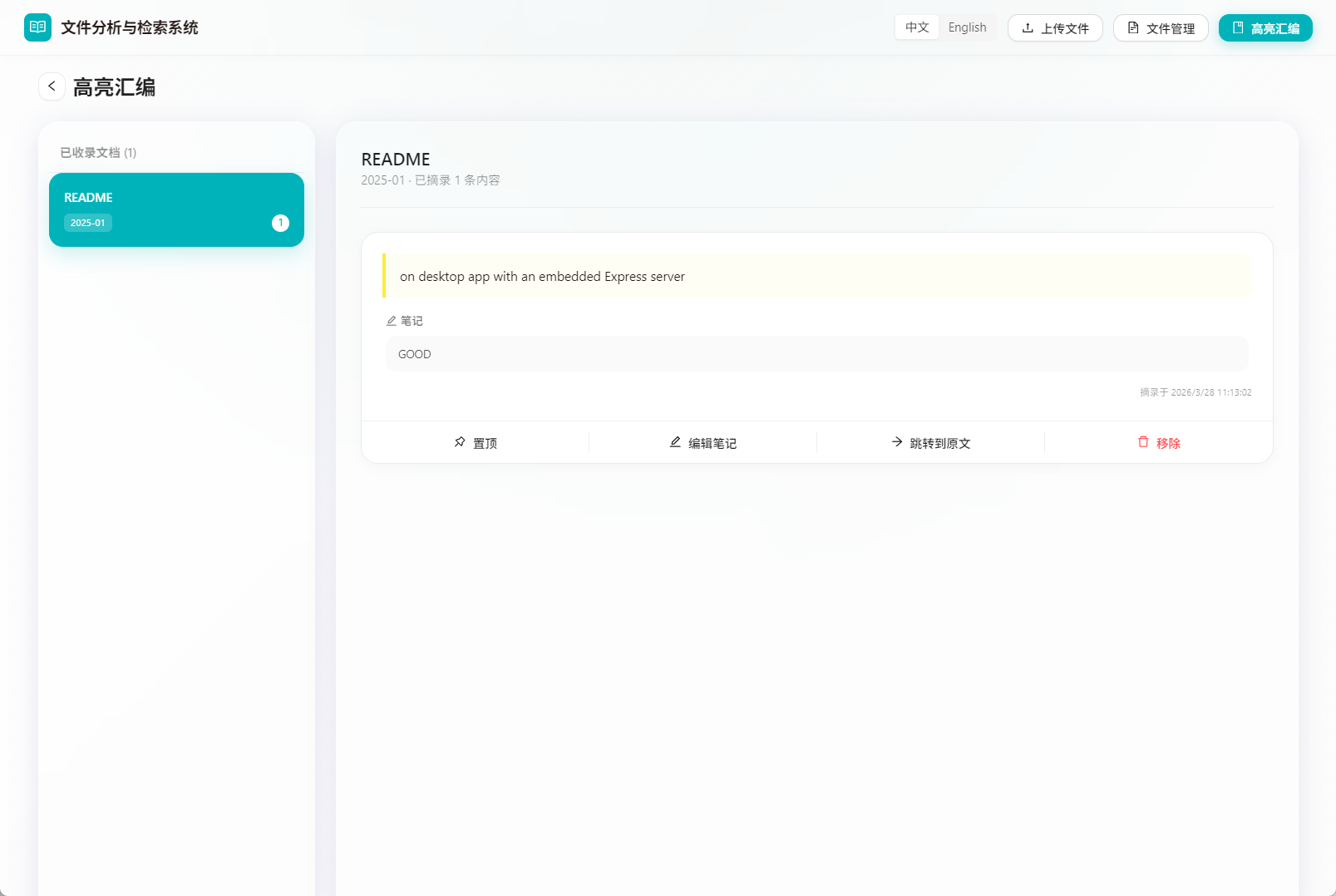
高亮汇编:把阅读过程变成可沉淀的知识片段
很多时候,我们看制度文件不是为了“读完”,而是为了提炼关键信息。
比如:
- 某条审批权限怎么写的
- 某条职责边界怎么规定的
- 某一版制度和上一版有哪些值得关注的变化
所以 RuleScope 里我加了一个 高亮汇编 功能。
用户在正文里选中一段内容后,可以直接加入高亮汇编,并补充一条笔记。
这样一来,软件不只是“看文件”,还可以帮助做:
- 条款摘录
- 要点沉淀
- 复盘记录
- 制度学习笔记
中英文切换:虽然简单,但很实用
这个版本里我还补上了一个轻量的语言切换入口。
因为有些场景下,软件展示给不同使用者时,英文界面更适合演示、开源发布和产品展示。
现在顶部导航栏已经可以直接在:
- 中文
- English
之间切换。
这个功能不复杂,但它让整个项目在开源发布时更完整,也更适合作为公开作品展示。
便携版怎么用
为了尽量降低使用成本,我也打了一份 Windows 便携版。
使用方式非常简单:
- 下载 Release 中的便携版压缩包
- 解压整个目录
- 运行主程序
- 保持 exe 和
resources文件夹在一起
这种方式不需要安装,适合直接拷贝、试用和内部传播。
对于很多桌面工具来说,“能不能直接拿来跑”比“功能是否复杂”更重要。
这个项目已经开源
我已经把 RuleScope 开源到了 GitHub,仓库地址如下:
https://github.com/Pumatlarge/RuleScope
如果你对这些方向感兴趣,可以直接去看:
- Electron 桌面应用结构
- React + Express 的组合方式
- Word 自动编号提取与结构化处理
- 规章制度类文档的阅读器设计
一些适合继续迭代的方向
虽然目前已经能稳定完成核心流程,但这个项目还有不少值得继续打磨的空间,比如:
- 更完整的编号层级支持
- 更强的版本比对能力
- PDF 内容提取优化
- 更漂亮的多栏阅读体验
- 文档标签、分类与筛选
- 更正式的发布与自动打包流程
我自己比较感兴趣的,还是继续把“制度文档阅读”这件事做得更像一个真正的专业工具,而不仅仅是“能打开文件”。
最后
RuleScope 的出发点其实很简单:
不是让文档只是被保存下来,而是让文档真正变得可读、可找、可导航、可沉淀。
如果你也经常和规章制度、管理办法、细则、汇编类文档打交道,也许这个小工具会对你有帮助。